(간호연구) 가설 검증
데이터 분석 시 두 가지
– 확증적 자료분석 : 미리 가설들을 세운 다음 가설을 검증해 나가는 방식
– 탐색적 자료분석(EDA) : 가설을 먼저 정하지 않고 데이터를 탐색해 보면서 가설 후보들을 찾고 데이터의 특징을 찾는 것
가설설정(귀무가설, 대립가설)
– 귀무가설 : 통계학에서 처음부터 버릴 것을 예상하는 가설 – “새로운 광고 배너를 게재해도 기존과 차이가 없을 것이다.“
– 대립가설 : 귀무가설에 대립하는 명제 – “새로운 광고 배너를 게재하면 기존과 차이가 있을 것이다(다를 것이다).“
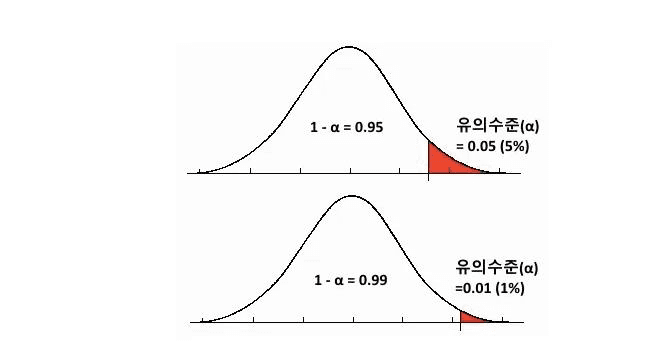
유의수준
– 정의 : 귀무가설(차이가 없을 것이라고 생각하는 가설)이 맞을 때 기각할 확률 → 결론은 귀무가설이 거짓이라는 것을 증명하는 범위
– 표기 : α
– 범용적기준 :
- 0.05(5%)
- 0.01(1%)
- 0.10(10%)
– 신뢰도와의 관계 : 95%의 신뢰도를 기준으로 한다면(1-0.95)인 0.05값 이유의 수준.
– 신뢰수준의 반대가 유의수준이다.
p-값(p-value)
– p-값(p-value)은 통계적 가설 검정에서 아주 중요한 개념이다. 간단히 말하면 :
– 정의 : 귀무가설이 참이라고 가정했을 때, 지금 관찰된 데이터(또는 더 극단적인 데이터)가 나올 확률
– 해석 :
– p-값이작다 → 이런 결과가 우연히 나올 가능성이 매우 낮음 → 귀무가설을 기각할 근거가 강함
– p-값이크다 → 관찰된 결과가 우연히 나올 가능성이 충분히 있음 → 귀무가설을 기각하기 어려움
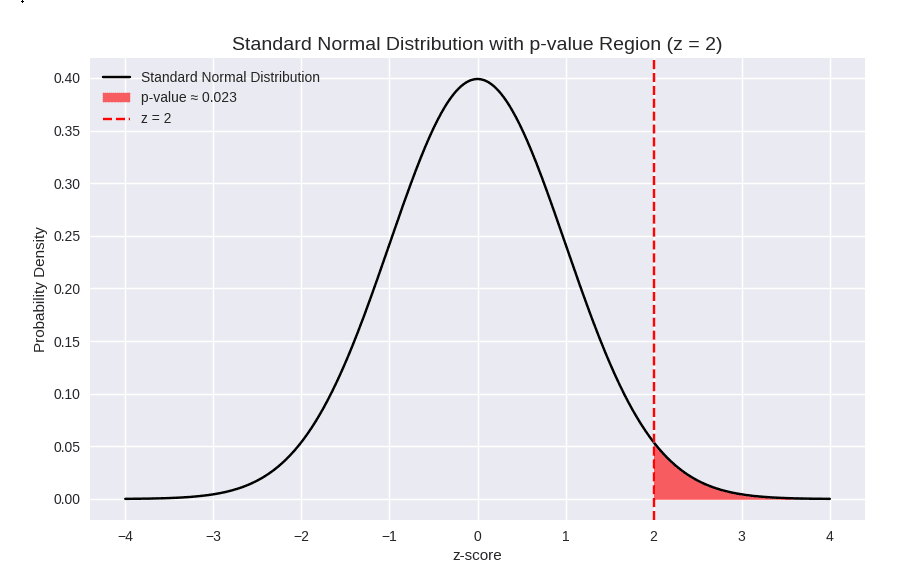
유의수준(α): 연구자가 미리 정하는 기준 (보통 0.05)판정 기준:
p < α → 귀무가설기각(통계적으로유의함)
p ≥ α → 귀무가설 유지 (통계적으로 유의하지 않음)
예시 : α=0.05, p=0.023 → p < α → 귀무가설 기각 → “평균과 유의하게 다르다”
가설설정
– 연구자의 목표 : 귀무가설을 기각하는 것
– 예시 : 새 수면제 개발
- H₀: “효과 없다” → 귀무가설(연구자의 반증 가설)
- H₁: “효과 있다” (연구자가 원하는 결론)
- 실제 연구자의 가설이 성립 하려면 유의수준으로 알 수 있다.
가설이 검증 수준=유의수준
| 유의수준 | 의미 | 비유 |
| α = 0.05 | 5%까지 틀릴 수 있음 | 일반적인 검증 |
| α = 0.01 | 1%만 틀릴 수 있음 | 엄격한 검증 |
| α = 0.10 | 10%까지 틀릴 수 있음 | 느슨한 검증 |
| 판정 | 통계 용어 | 쉬운 말 |
| H₀기각(귀무가설이 거짓) | “유의하다” (significant) | “효과 있다!” |
| H₀채택(귀무가설이 참) | “유의하지 않다” | “효과 없다고 결론”(증거 불충분) |
정규분포
– 자료의 분포는 자료가 어떻게 분포되어 있는지를 의미
– 종 모양이며 가운데를 중심으로 양쪽이 대칭이다.
– 평균, 최빈치, 중앙값이 가운데에서 모두 일치한다.
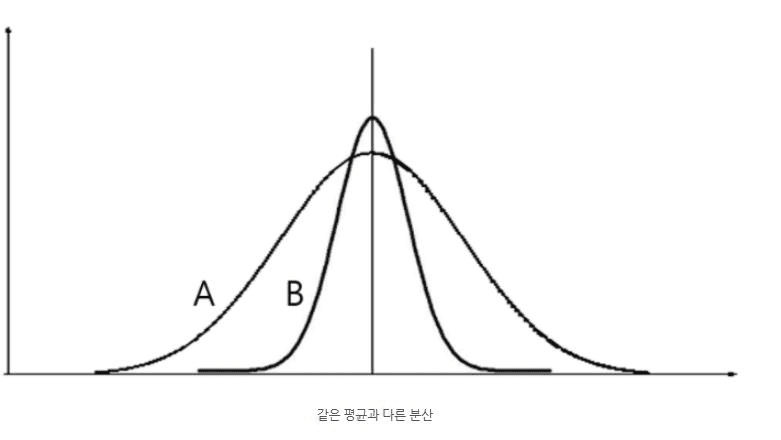
– 분포의 모양은 평균과 표준편차에 의하여 달라진다.
– 평균은 같아도 표준편차가 크면 펑퍼짐한 모양이 되고, 표준편차가 작으면 뽀족한 모양이 된다.
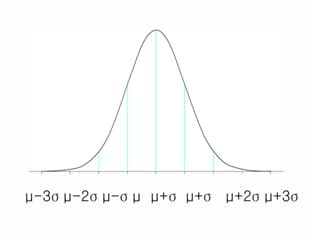
정규분포의 특징 (3가지)
① 종 모양 (가운데가 볼록)
– 가운데(평균)에 데이터가 가장 많이 모임
– 멀어질수록 데이터가 점점 줄어듦
② 좌우 대칭
– 평균을 중심으로왼쪽과 오른쪽이 똑같은 모양
③ 평균 = 중앙값 = 최빈값
– 세 값이 모두같은 곳에 위치
표준편차
– 표준편차는 데이터가 평균으로부터 얼마나 퍼져 있는지(흩어져 있는지)를 나타내는 통계 지표이다.
– 쉽게 말하면, 데이터의 흔들림 정도, 변동성의 크기를 수치로 표현한 것.
| 표준편차(σ) | 의미 | 그래프 모양 |
| 작음 | 데이터가 평균 주변에 모여 있음 | 뾰족하고 좁음 |
| 큼 | 데이터가 널리 퍼져 있음 | 낮고 넓음 |
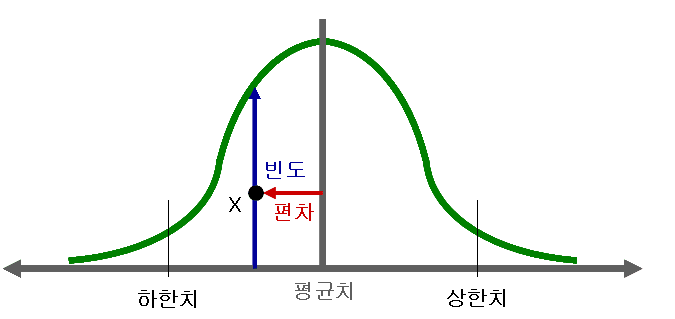
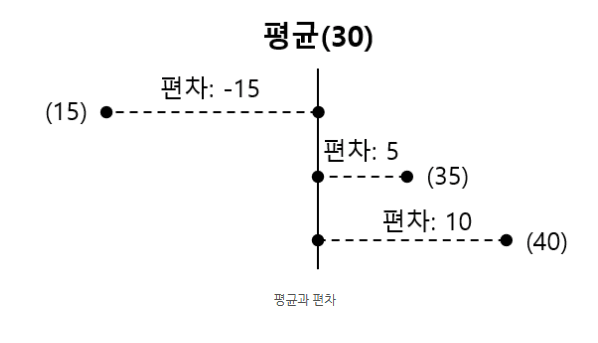
편차
– “편차가 크다”는 말은 데이터나 값들이 평균(또는 기준점)에서 많이 벌어져 있다는 뜻이다. 즉, 변동성이 크다는 의미로 이해할 수 있다.
– 시험 점수에서 편차가 크다는 것은 학생들의 점수가 평균 근처에 몰려 있지 않고, 어떤 학생은 매우 높고 어떤 학생은 매우 낮다는 뜻이다.
– 제품 품질에서 편차가 크다면, 생산된 제품마다 품질 차이가 심해서 균일하지 않다는 의미가 된다.
– 주식 수익률에서 편차가 크면, 수익이 들쭉날쭉해서 안정적이지 않다는 뜻이다.
– 즉, 편차가 크다 = 데이터가 흩어져 있다, 안정성이 낮다, 일관성이 부족하다로 요약할 수 있다.
표준정규분포 (Z분포)
– 정규분포 = 종 모양, 좌우 대칭
– 평균(μ)에 가장 많은 데이터가 모임
– 멀어질수록 데이터 급감
– 표준정규분포 = 평균 0, 표준편차 1
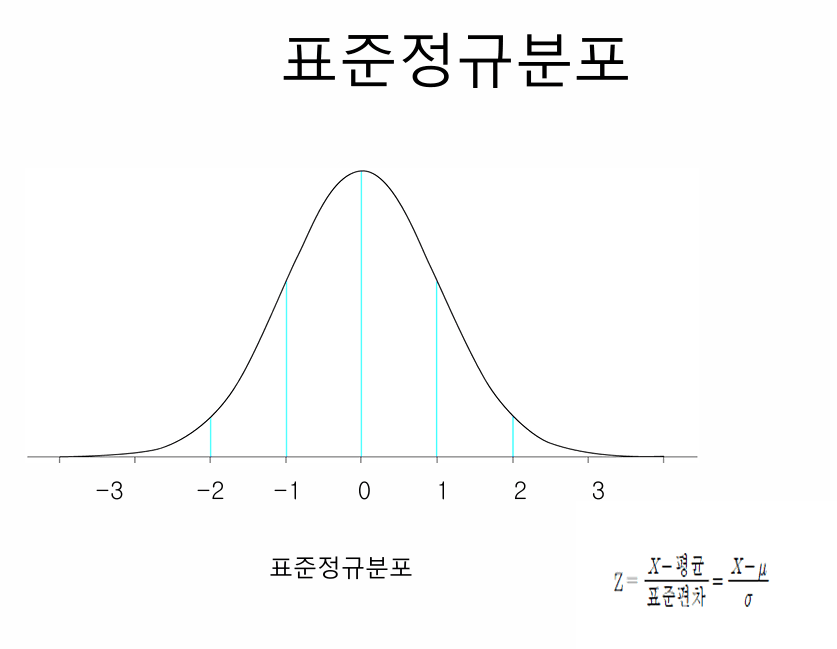
Z값
– Z값 = “평균에서 떨어진 거리를 그 집단의 표준편차라는 눈금자로 잰 값
– Z값은 특정 데이터가 평균으로부터 얼마나 떨어져 있는지를 표준편차 단위로 나타낸 값
– 즉, 데이터가 분포 내에서 상대적으로 어디에 위치하는지를 보여주는 표준화된 점수이다.
– z값이 0 → 평균과 동일
– z값이 양수 → 평균보다 큼
– z값이 음수 → 평균보다 작음
– z값의 절댓값이 클수록 평균에서 멀리 떨어져 있음
(즉, 특이한 값일 가능성이 큼)
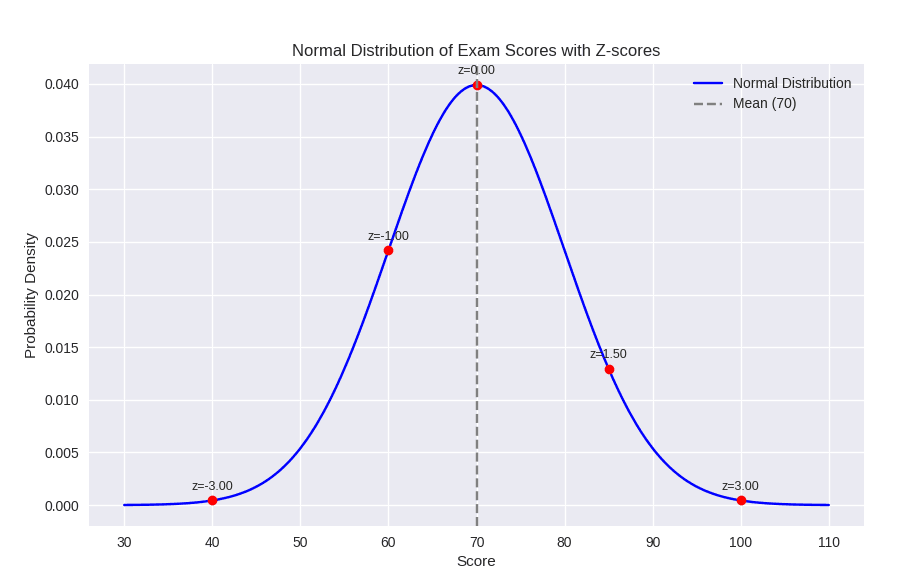
Z score
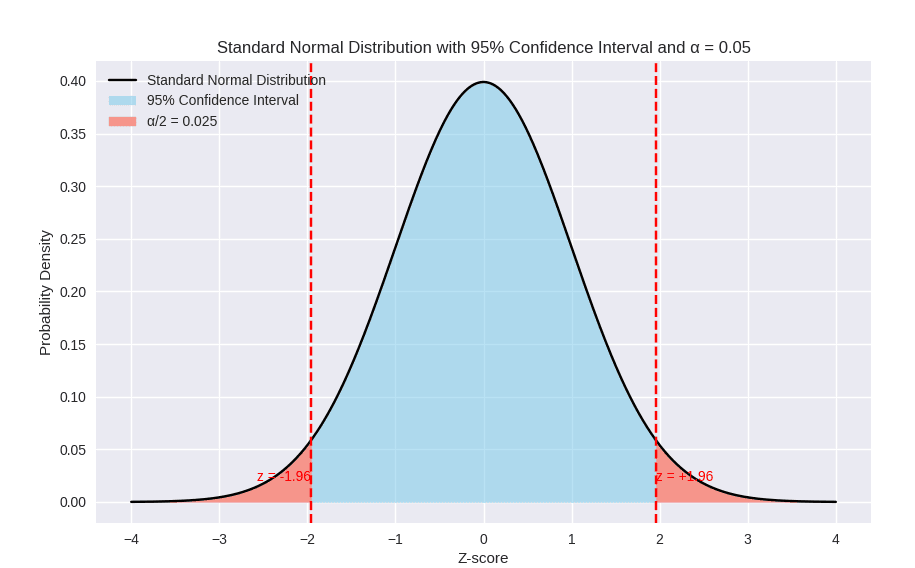
– 곡선 중앙: 평균(μ=0), z=0파란색 영역: -1.96 ≤ z ≤ +1.96
→ 전체 데이터의 약 95% 포함
– 빨간색 꼬리 영역: z < -1.96 또는 z > +1.96 → 각각 2.5% 확률, 합쳐서 5% (α=0.05) → 유의수준
– 점선: z=-1.96, z=+1.96 → 신뢰구간 경계선
유의수준(α)의 의미
– 유의수준 α=0.05: 가설검정에서 “우연히 이런 극단적인 값이 나올 확률이 5% 이하라면, 귀무가설을 기각한다”는 기준
– 좌측 꼬리(α/2=0.025): 평균보다 매우 작은 값이 나올 확률
– 우측 꼬리(α/2=0.025): 평균보다 매우 큰 값이 나올 확률
– z=±1.96은 95% 신뢰구간의 경계값이며, 그 바깥쪽 꼬리 영역이 유의수준 α=0.05를 나타냅니다.
– z값은 데이터가 평균에서 얼마나 떨어져 있는지를 표준화된 기준으로 보여주며, 통계적 판단(신뢰구간, 유의수준, 이상치 판별)의 핵심 도구
Z값의 의미
1) 비교 가능성 확보
– 서로 다른 단위나 척도의 데이터를 표준편차 단위로 환산해 비교할 수 있다.
예: 키(cm)와 시험 점수(점수)를 직접 비교할 수 없지만, z값으로 환산하면 “평균에서 얼마나 벗어났는가”라는 동일 기준으로 비교 가능해진다.
2) 이상치(outlier) 탐지
– z값이 크거나 작으면 평균에서 멀리 떨어진 값 → 극단적인 데이터로 판별 가능
예: z값이 ±3 이상이면 흔히 이상치로 간주한다.
3) 가설검정과 신뢰구간
– z=±1.96은 95% 신뢰수준의 기준점
– 통계적 유의성을 판단할 때 “데이터가 평균에서 우연히 나올 수 있는 범위인지, 아니면 특별한 의미가 있는지”를 결정하는 데 사용된다.
4) 실제 적용 분야
– 교육: 학생 성적을 상대평가할 때
– 품질 관리: 제품이 허용 오차 범위를 벗어났는지 판정
– 금융: 주가 변동이 평균적 범위를 벗어났는지 확인
모집단 표준편차(σ)를 알고 있을 때
– 개별 값𝑥에 대한 Z값 (표준화 점수)
– 𝑍=𝑥−𝜇𝜎
- 𝑥: 개별 측정값
- 𝜇: 모집단 평균
- 𝜎: 모집단 표준편차
– 의미 : 평균(μ)으로부터 표준편차(σ) 단위로 얼마나 떨어져 있는가?
- 간호사들이 제발 하지 말아달라는 운동
- (약리학) 감염과 암 치료 약물 03 – 향균제 02
- 10대들 사이에 퍼지는 마약의 형태
- (약리학) 감염과 암 치료 약물 02 – 향균제 단백합성 억제제
- 김웅한 교수 일화 “수술 실패하면 당신 죽일 거고 나도 죽는 거야!”